The amount of data generated daily is around 2.5 quintillion bytes – a mind-boggling volume that is too big for the human brain to conceptualize in a concrete way. Every click, every tweet, every transaction, and every sensor signal contributes to an ever-growing mountain of data.
This flood of “big data”, as it’s known, presents challenges regarding data collection, storage, and analysis. For starters, gathering this data demands robust systems that can handle its volume and complexity. Then, there's the issue of storage – keeping exabytes of data requires huge resources and efficient ways to access and manage it. But the biggest challenge comes down to analysis. Traditional methods can’t keep up, especially when it comes to textual materials.
That's where text analytics and natural language processing (NLP) comes into play. These technologies represent a burgeoning area of data science that makes extracting valuable information from raw unstructured text possible. From named entity linking to information extraction, it's time to dive into the techniques, algorithms, and tools behind modern data interpretation.
The value of data – a strategic investment
The landscape is ripe with opportunities for those keen on crafting software that capitalizes on data through text mining and NLP. Companies that broker in data mining and data science have seen dramatic increases in their valuation. That's because data is one of the most valuable assets in the world today.
Data is not just a useless byproduct of business operations but a strategic resource fueling innovation, driving decision-making, and unlocking new opportunities for growth.
Businesses that effectively harness the power of data gain a competitive edge by gaining insights into customer behavior, market trends, and operational efficiencies. As a result, investors and stakeholders increasingly view data-driven organizations as more resilient, agile, and poised for long-term success.
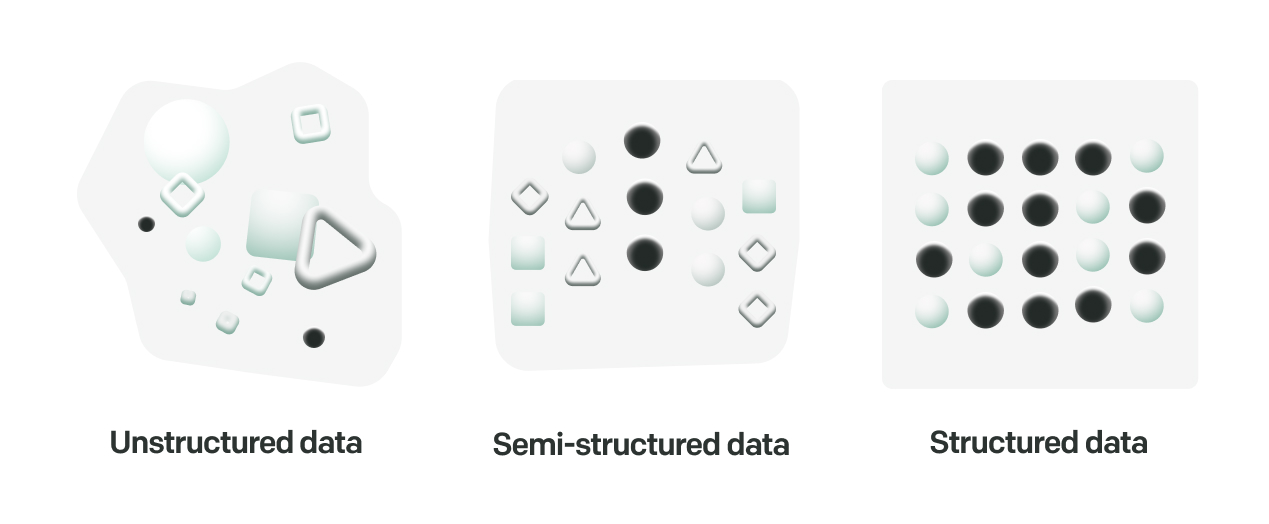
The diversity of data
Data can be broadly categorized into three main types: unstructured, structured, and semi-structured. We've become quite comfortable handling structured data using conventional database tools. The other two types, especially unstructured data, require more sophisticated analysis techniques.
Unstructured data
Unstructured data doesn’t follow a specific format or structure – making it the most difficult to collect, process, and analyze data. It represents the bulk of data generated daily; despite its chaotic nature, unstructured data holds a wealth of insights and value. Unstructured text data is usually qualitative data but can also include some numerical information.
Examples include:
- Text – Emails, articles, blog posts, and social media updates where the format varies widely and can include a mix of emojis, text, and hashtags.
- Multimedia – Images, audio files, and videos.
- Web pages – The content of web pages usually includes a mix of text, images, and dynamic content that cannot be easily cataloged into predefined tables and rows.
- Documents – PDFs, Word documents, Google Docs, and PowerPoint presentations contain a mix of text, images, and formatting.
- Sensor data – IoT device readings often become unstructured once combined with other data types or collected in a massive, heterogeneous dataset.
Structured data
Structured data is highly organized and easily understandable by computers because it follows a specific format or schema. This type of data is much more straightforward because it is typically stored in relational databases as columns and rows, allowing for efficient processing and analysis. Structured data encompasses both numerical data and qualitative data.
Examples include:
- Customer information – Names, addresses, phone numbers, and email addresses stored in a customer relationship management (CRM) system.
- Financial records – Banking transactions, stock prices, and accounting records, where each entry is clearly defined in terms of amount, date, transaction type, etc.
- Inventory data – Product listings in an inventory database, including product IDs, descriptions, quantities, and prices.
Semi-structured data
Semi-structured data falls somewhere between structured and unstructured data. While it does not reside in a rigid database schema, it contains tags or other markers to separate semantic elements and enable the grouping of similar data.
Examples include:
- JSON files – Widely used in web applications for data interchange, JSON files structure data as attributed-value pairs.
- XML documents – Provides a framework for describing data with tags, allowing for hierarchical information organization.
- HTML – Embeds data within tags, providing a semi-structured format for mining information from websites.
The challenges of linguistic data
Unlike structured numerical data, linguistic data is inherently complex, nuanced, and often ambiguous:
- Variability and richness of human language, which includes slang, dialects, colloquialisms, and cultural nuances.
- Lack of standardization, leading to wide variety in terms of syntax, grammar, spelling, and punctuation.
- Contextual ambiguity, where the meaning of words or phrases can vary depending on the surrounding content.
- Noise or irrelevant information, such as typographical errors, formatting inconsistencies, or extraneous content within the text.
Humans handle linguistic analysis with relative ease, even when the text is imperfect, but machines have a notoriously hard time understanding written language. Computers need patterns in the form of algorithms and training data to discern meaning.
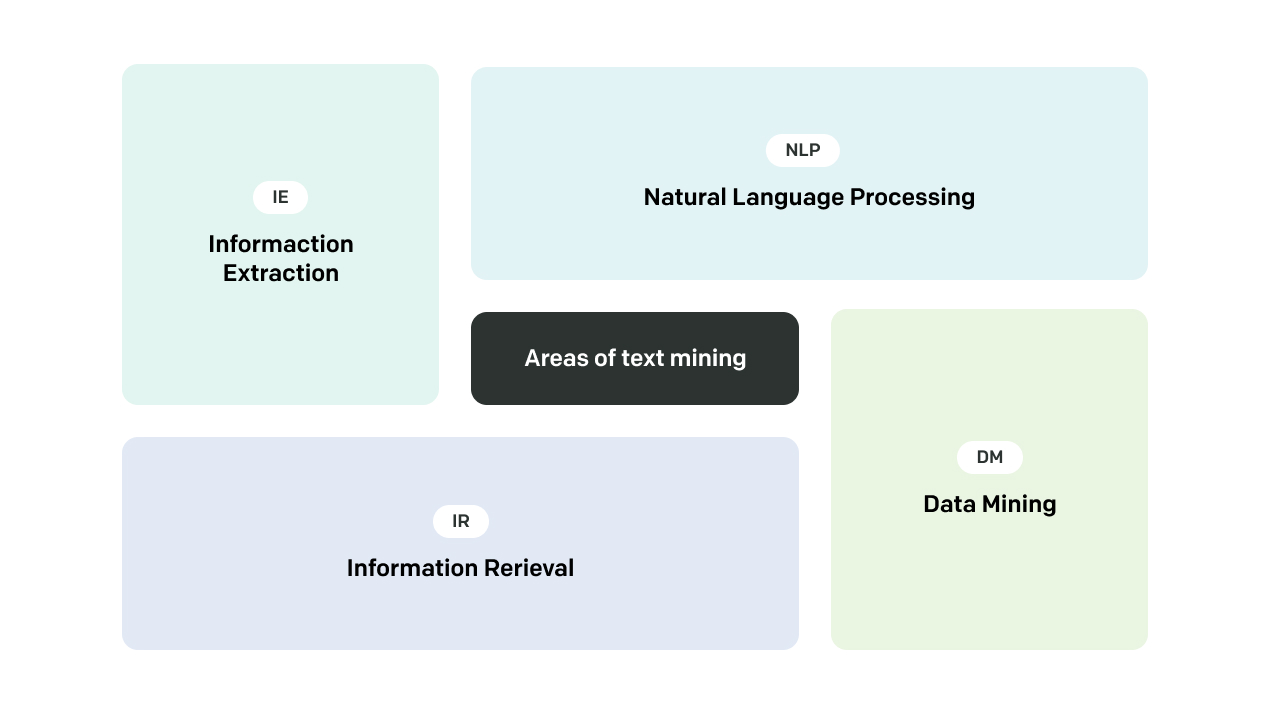
What is natural language processing?
Natural language processing (NLP) covers the broad field of natural language understanding. It encompasses text mining algorithms, language translation, language detection, question-answering, and more. This field combines computational linguistics – rule-based systems for modeling human language – with machine learning systems and deep learning models to process and analyze large amounts of natural language data.
What is text mining?
Text mining, also known as text data mining or text analytics, sits at the crossroads of data analysis, machine learning, and natural language processing. Text mining is specifically used when dealing with unstructured documents in textual form, turning them into actionable intelligence through advanced text mining capabilities and various techniques and algorithms.
Text mining is an evolving and vibrant field that's finding its way into numerous applications, such as text categorization and keyword extraction. Though still in its early stages, it faces a variety of hurdles that the community of researchers is working to address.
One major challenge is the overwhelming volume and diversity of textual data, demanding advanced processing methods to manage effectively. Another is associated with the nature of human language, which we've already discussed. Despite these challenges, text mining is expected to continue to progress rapidly.
Text mining vs data mining
While both text mining and data mining aim to extract valuable information from large datasets, they specialize in different types of data.
Data mining primarily deals with structured data, analyzing numerical and categorical data to identify patterns and relationships. Text mining specializes in unstructured textual data, using NLP techniques to understand and interpret the intricacies of human language.
Six NLP techniques you should know
These techniques are laid out from the simplest to the most complex. The goal is to guide you through a typical workflow for NLP and text mining projects, from initial text preparation all the way to deep analysis and interpretation.
1. Tokenization
Computers don't naturally grasp textual data as a cohesive whole. Instead, computers need it to be dissected into smaller, more digestible units to make sense of it. This process is known as tokenization. Tokenization breaks down streams of text into tokens – individual words, phrases, or symbols – so algorithms can process the text, identifying words.
Tokenization sounds simple, but as always, the nuances of human language make things more complex. Consider words like "New York" that should be treated as a single token rather than two separate words or contractions that could be improperly split at the apostrophe.
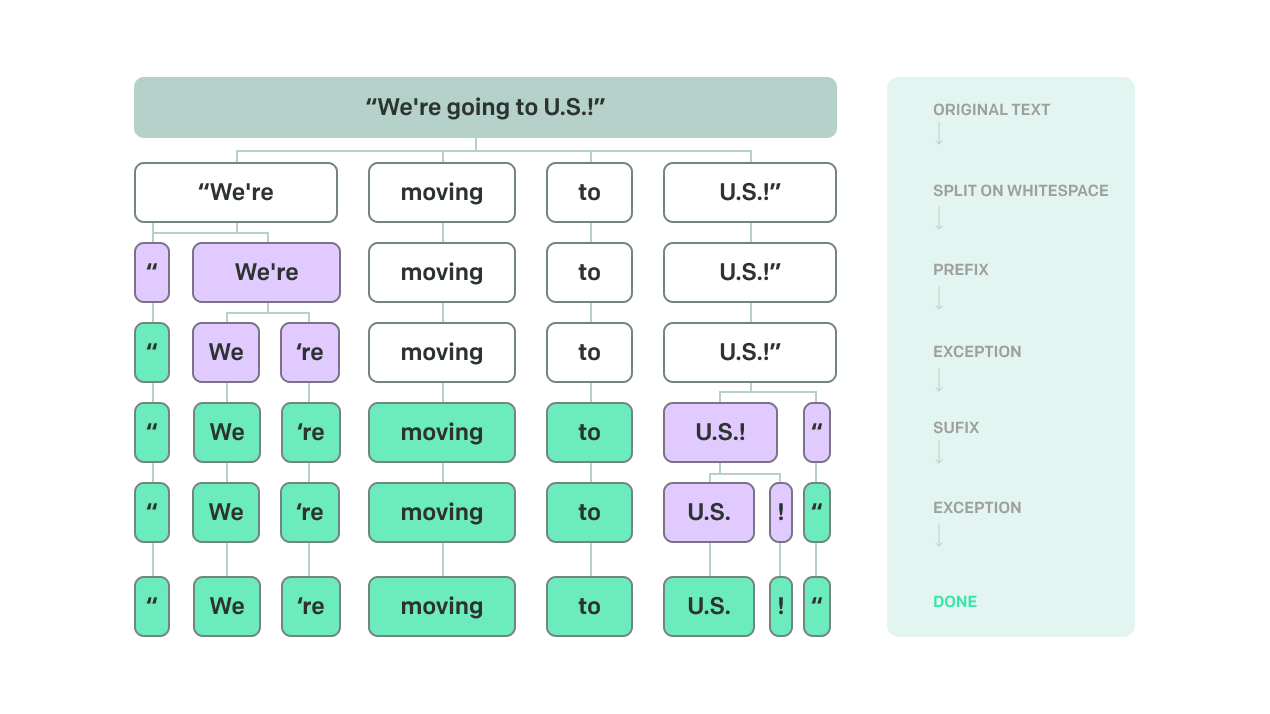
Popular NLP libraries such as NLTK, spaCy, and TensorFlow offer built-in functions for tokenization, but custom tokenizers may be needed to handle specific texts.
2. Part-of-speech tagging
Once a text has been broken down into tokens through tokenization, the next step is part-of-speech (POS) tagging. Each token is labeled with its corresponding part of speech, such as noun, verb, or adjective. Tagging is based on the token's definition and context within the sentence. POS tagging is particularly important because it reveals the grammatical structure of sentences, helping algorithms comprehend how words in a sentence relate to one another and form meaning.
English is filled with words that can serve multiple grammatical roles (for example, run can be a verb or noun). Determining the correct part of speech requires a solid understanding of context, which is challenging for algorithms. POS tagging models are trained on large data sets where linguistic experts have labeled the parts of speech.
3. Named entity linking
Next on the list is named entity linking (NEL) or named entity recognition. NEL involves recognizing names of people, organizations, places, and other specific entities within the text while also linking them to a unique identifier in a knowledge base. For example, NEL helps algorithms understand when "Washington" refers to the person, George Washington, rather than the capital of the United States, based on context.
NLP libraries and platforms often integrate with large-scale knowledge graphs like Google's Knowledge Graph or Wikidata. These extensive databases of entities and their identifiers offer the resources to link text references accurately.
4. Coreference resolution
When humans write or speak, we naturally introduce variety in how we refer to the same entity. We weave in pronouns, names, and descriptors. For instance, a story might initially introduce a character by name, then refer to them as "he," "the detective," or "hero" in later sentences. Coreference resolution is the NLP technique that identifies when different words in a text refer to the same entity.
While coreference resolution sounds similar to NEL, it doesn't lean on the broader world of structured knowledge outside of the text. It is only concerned with understanding references to entities within internal consistency.
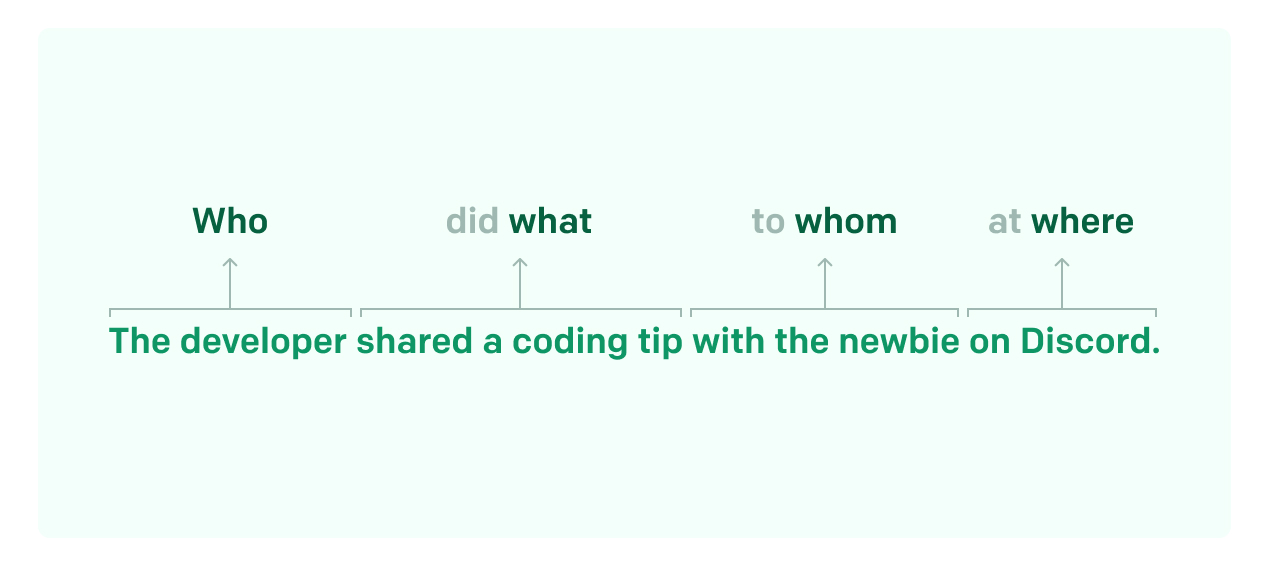
5. Semantic role labeling (SRL)
Now we encounter semantic role labeling (SRL), sometimes called "shallow parsing." SRL identifies the predicate-argument structure of a sentence – in other words, who did what to whom.
Consider the following sentence:
- The chef cooked the meal.
Semantic role labeling would identify "the chef" as the doer of the action, "cooked" as the action, and "the meal" as the entity the action is performed on.
Training data is also used to create SRL models. Texts are first annotated by experts to include various sentence structures and semantic roles. The effectiveness of an SRL model hinges on the diversity and quality of its training data. The more varied and comprehensive the examples it learns from, the better the model can adapt to analyze a wide range of texts.
6. Language modeling
Language modeling is the development of mathematical models that can predict which words are likely to come next in a sequence. It's about building a statistic map of language. After reading the phrase "the weather forecast predicts," a well-trained language model might guess the word "rain" comes next.
These models are the foundation for a wide array of natural language generation applications, from autocomplete features in search engines and text editors to more complex tasks like machine translation and speech recognition.
Deep learning has made major strides in this area in recent years. Recurrent neural networks (RNNs), bidirection encoder representations from transformers (BERT), and generative pretrained transformers (GPT) have been the key. Transformers have enabled language models to consider the entire context of a text block or sentence all at once.
Three text mining methods you should know
Once you understand the basic and advanced NLP methods, it's time to dig into the three main text mining techniques: sentiment analysis, topic modeling, and information extraction.
1. Sentiment analysis
Sentiment analysis is a text mining technique used to determine the emotional tone behind a body of text. Sentiments can be categorized as positive, negative, or neutral. More advanced analysis can understand specific emotions conveyed, such as happiness, anger, or frustration. Sentiment analysis is no small feat. It requires the algorithm to navigate the complexities of human expression, including sarcasm, slang, and varying degrees of emotion.
Sentiment analysis applications:
- Brand monitoring – Companies can use sentiment analysis to keep a pulse on what customers are saying about them on social media posts, forums, and online reviews. By analyzing customer reviews, brands can identify improvement areas and respond proactively.
- Market research – Sentiment analysis helps businesses grasp consumer preferences and trends, understand customer surveys and customer feedback, and tailor offerings and marketing strategies more effectively.

2. Topic modeling
Topic modeling brings order to chaos. This advanced text mining technique can reveal the hidden thematic structure within a large collection of documents. Sophisticated statistical algorithms (LDA and NMF) parse through written documents to identify patterns of word clusters and topics. This can be used to group documents based on their dominant themes without any prior labeling or supervision.
For example, in a large collection of scientific literature, topic modeling can separate journal articles into key concepts or topics, such as "climate change impacts." Each topic would be marked by a distinct set of terms. For the climate change topic group, keyword extraction techniques may identify terms like "global warming," "greenhouse gases," "carbon emissions," and "renewable energy" as being relevant.
Topic modeling applications:
- Content recommendation – Understanding the main themes within a written text can enhance content recommendation engines. If a user reads several articles clustered around the topic of "machine learning," the system can recommend other articles from the same topic cluster.
- Customer feedback analysis – Topic modeling can sift through reviews and customer surveys to identify common themes, such as product features that customers love or issues that need addressing. This helps businesses prioritize improvements and understand customer needs better.
3. Information extraction (IE)
Information extraction automatically extracts structured information from unstructured text data. This includes entity extraction (names, places, and dates), relationships between entities, and specific facts or events. It leverages NLP techniques like named entity recognition, coreference resolution, and event extraction.
Information extraction applications
- Business intelligence – Especially valuable from a BI perspective because it can automate and streamline tasks like document summarization, media analysis, and market intelligence, transforming unstructured text documents into structured, actionable insights. By using this information retrieval method, businesses can significantly reduce the time and resources spent on manual data mining and analysis.
- Healthcare – Can parse through unstructured text data such as clinical notes, lab reports, and diagnostic imaging reports. Once the relevant information is extracted, it can be structured and organized into a format compatible with healthcare information systems or databases. These electronic health records (EHRs) can support clinician decisions, disease monitoring, and tailored treatment plans.
- Risk management – Can identify potential risks and compliance issues by extracting information from textual data sources such as legal documents, contracts, and incident reports. IE algorithms can identify key risk indicators, contractual obligations, regulatory requirements, and other adverse events that might impact an organization's reputation or operations.
Business benefits of text mining
Text mining offers a variety of business benefits, making it an invaluable tool for modern companies. By analyzing customer feedback and social media posts, businesses can gain insights into customer needs and preferences, enabling them to tailor their products and marketing strategies more effectively. This leads to improved customer service and enhanced product development. Additionally, text mining can identify areas for process improvement, helping businesses optimize their operations and increase efficiency.
Whether it’s through sentiment analysis, topic modeling, or information extraction, text mining is a great business opportunity for any company to turn unstructured text data into structured and strategic assets.
Text mining tools available to you
For developers seeking powerful text mining and analytics, various tools are at your disposal. From Python libraries to open-source platforms and comprehensive monetization platforms – you can choose the text mining tool that meets your needs:
Natural Language Toolkit (NLTK)
A popular Python library that offers a wide range of text analysis and NLP functionalities, including tokenization, stemming, lemmatization, POS tagging, and named entity recognition.
spaCy
Well-known NLP Python library with pre-trained models for entity recognition, dependency parsing, and text classification. It is the preferred choice for many developers because of its intuitive interface and modular architecture.
GATE (General Architecture for Text Engineering)
This open-source text mining software supports various languages and includes modules for entity recognition, coreference resolution, and document classification. It also has a GUI for building and configuring text processing pipelines.
Text Platform
This versatile platform is designed specifically for developers looking to expand their reach and monetize their products on external marketplaces. The Text Platform offers multiple APIs and SDKs for chat messaging, reports, and configuration. The platform also provides APIs for text operations, enabling developers to build custom solutions not directly related to the platform's core offerings.
TensorFlow Text
This library is built on top of TensorFlow, uses deep learning techniques, and includes modules for text classification, sequence labeling, and text generation.
The future of text mining
The future of text mining is brimming with potential. As the availability of text data continues to grow and advancements in NLP and machine learning accelerate, text mining is becoming more powerful and accessible. We can expect to see its adoption across various industries, including healthcare, finance, and marketing, where it will drive new applications and use cases. The integration of text mining with other technologies like artificial intelligence and the Internet of Things will open up new frontiers and enable more sophisticated and automated analysis of text data. Text mining enables businesses to harness the full potential of the treasure trove they already own — their data.
Frequently Asked Questions
1. What field does NLP fall under?
Natural language processing is a subfield of computer science, as well as linguistics, artificial intelligence, and machine learning. It focuses on the interaction between computers and humans through natural language.
2. How does text mining differ from NLP?
Text mining is more of a subset of NLP. Text mining focuses specifically on extracting meaningful information from text, while NLP encompasses the broader purview of understanding, interpreting, and generating human language.
3. Can NLP and text mining be used for predictive analytics?
Yes, both text mining technology and NLP can be used to predict future trends and behaviors. Whether it's predicting consumer behaviors or market trends, these technologies convert raw text into strategic foresight.
4. What are some text mining algorithms?
Term frequency-inverse document frequency (TF-IDF) evaluates word importance within documents, while the Latent Dirichlet Allocation (LDA) algorithm uncovers underlying topics by clustering similar words.


